Arm AGI CPU
ARM AGI CPU WORLD`S MOST EFFICIENT AGENTIC CPU
Introducing the Arm AGI CPU
ARM AGI CPU WORLD`S MOST EFFICIENT AGENTIC CPU




The Dawn of the Agentic Era: Arm’s AGI CPU
The landscape of artificial intelligence is shifting from passive chatbots to autonomous agents—entities capable of reasoning, planning, and executing complex tasks with minimal human intervention. At the heart of this revolution lies a critical hardware challenge: how do we provide the massive compute required for "agentic" workflows without melting the data center?
Arm has answered the call with its latest breakthrough: the Arm AGI CPU, officially dubbed the world’s most efficient agentic CPU.
Built for Reasoning, Not Just Processing
Traditional CPUs are designed for general-purpose tasks, but agentic AI requires a specific balance of high-frequency single-thread performance and massive memory bandwidth to handle long-context reasoning.
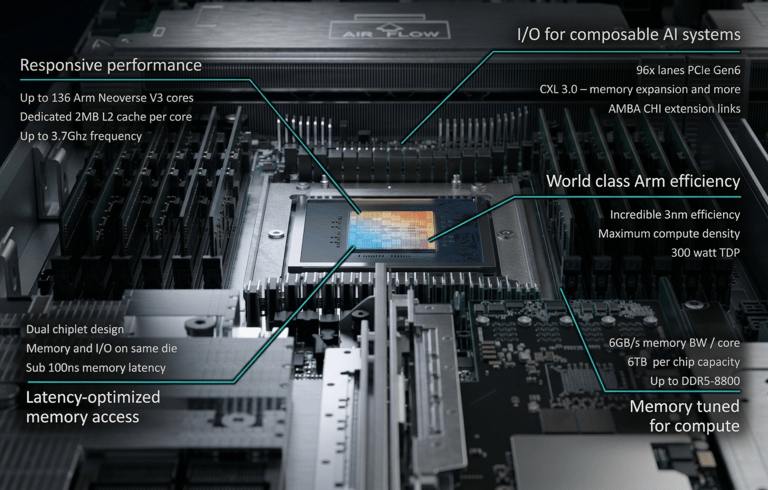
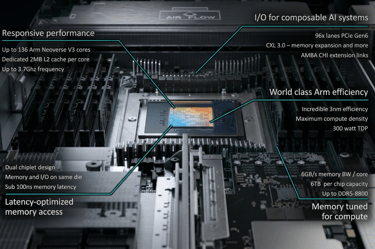
Responsive Performance: Leveraging up to 136 Neoverse V3 cores, this chip is optimized for the heavy lifting involved in AI decision-making.
Latency-Optimized Memory: With sub-100ns memory latency and support for DDR5-8800, the AGI CPU ensures that AI agents can "think" in real-time, reducing the lag between a prompt and an action.
Efficiency is the New Currency
As AI models scale, power consumption has become the industry's greatest bottleneck. The Arm AGI CPU tackles this with incredible 3nm efficiency, delivering maximum compute density within a manageable 300-watt TDP.
"Efficiency isn't just about saving power; it's about enabling the next generation of composable AI systems that can run 24/7 without the overhead of traditional high-heat architectures."
Why it Matters
By integrating I/O for composable AI systems and utilizing CXL 3.0 for seamless memory expansion, Arm is providing the blueprint for the next decade of infrastructure. This isn't just a faster processor; it is the foundational engine for Artificial General Intelligence (AGI), where efficiency and agency finally meet.
The future of AI won't just be intelligent—it will be autonomous, and it will run on Arm.
Efficient cores
Responsive performance
Up to 136 Arm Neoverse V3 cores
Dedicated 2 MB L2 cache per core
Up to 3.2 GHz frequency
Elegant efficiency
High instruction-per-cycle execution
TSMC 3 nm process
TDP 300W
Tuned memory architecture
Scaled for performance
6 GB/s memory bandwidth per core
Up to DDR5-8800
Latency-optimized
Integrated chiplet design
Compute and memory on the same die
Sub-100 ns memory latency
Flexible I/O
Designed for composable AI systems
96 PCIe Gen6 lanes
CXL 3.0 for memory expansion and pooling
AMBA CHI Extension Links for accelerator attach
Rack-scale economics
High performance at high utilization
Eliminates over-provisioning
Efficient TCO without performance penalty